Поиск / RAG
Ответы, основанные на ваших собственных знаниях
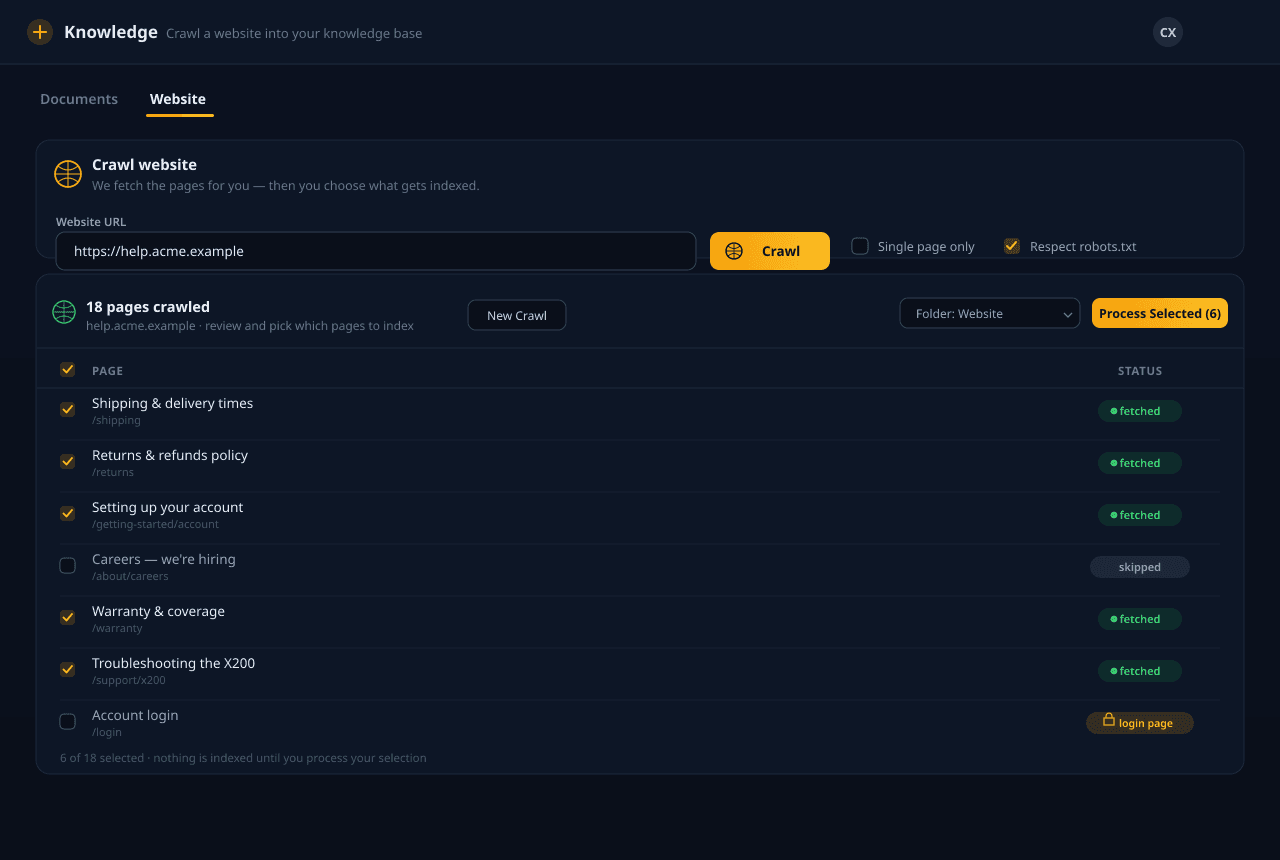
Загрузите документы, укажите нам сайт или синхронизируйте облачное хранилище. Мы разбираем, разбиваем на фрагменты, обогащаем и встраиваем всё — а затем извлекаем нужные фрагменты в момент запроса, чтобы ваш агент отвечал по тому, что вы действительно написали, а не на основе догадок.
Посмотрите, как работает опора на источники
Ответы из ваших источников, а не догадки
Задайте агенту вопрос и увидите, откуда берётся ответ — из ваших же загруженных документов, сайтов и файлов, а не из выдуманного текста.
Ваш агент по знаниям
Обоснуйте ответы агента вашими знаниями
Обоснуйте ответы агента вашими знаниями
Что делает поисковый стек
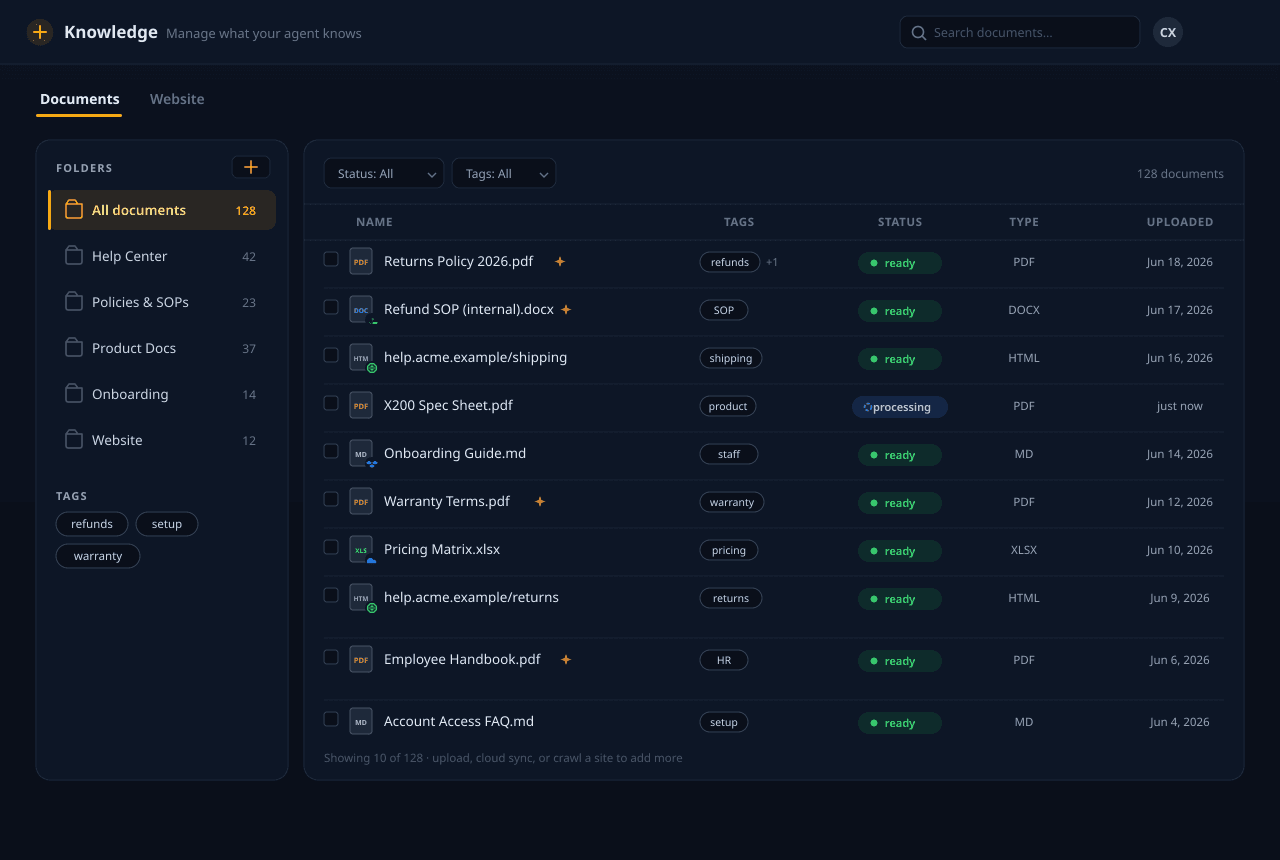
Принимает что угодно
PDF, документы Office, Markdown, HTML и целые сайты — плюс синхронизация с Google Drive, Dropbox, OneDrive и Box. На платных планах мы читаем даже отсканированные PDF и PDF на основе изображений, сложные таблицы и рукописный текст, которые обычные парсеры пропускают. Мы направляем каждый файл к нужному парсеру и держим всё в синхронизации с источником.
Контекстное разбиение на фрагменты
Документы делятся на перекрывающиеся фрагменты с учётом иерархии, и каждый фрагмент обогащается коротким сводным контекстом перед встраиванием — чтобы фрагмент сохранял смысл сам по себе, когда извлекается вне порядка.
Гибридный поиск
Каждый запрос параллельно выполняет плотный векторный поиск и поиск по ключевым словам (BM25), затем объединяет результаты — улавливая и смысловые совпадения, и точные термины вроде кодов товаров или строк ошибок, которые чистые векторы пропускают.
Переранжирование
Кросс-энкодер заново ранжирует объединённых кандидатов относительно самого вопроса, поднимая действительно релевантные фрагменты наверх ещё до того, как они попадут в модель — меньше промахов, точнее ответы.
Родительский контекст
Когда совпадает небольшой фрагмент, мы подтягиваем окружающий его родительский раздел, чтобы модель видела мысль целиком, а не обрезанное предложение — основание, которое читается так, будто оно поняло всю страницу.
Поиск с изоляцией арендаторов
Каждый поиск ограничен вашей организацией. Ваша база знаний никогда не смешивается с базой другого арендатора, никогда не используется для обучения моделей и удаляется по запросу.
От загрузки до обоснованного ответа
Индексирование происходит один раз при загрузке; извлечение — на каждый вопрос. Более высокие тарифы открывают глубокие режимы запросов, добавляющие шаги вроде декомпозиции и более широкого переранжирования — немного жертвуя скоростью ради более тщательных ответов.
Разобрать и разбить
Каждый источник разбирается по формату и делится на фрагменты с учётом иерархии и перекрытием, сохраняя заголовки и структуру.
Обогатить и встроить
Каждый фрагмент получает короткий сводный контекст, затем встраивается и загружается в векторное хранилище — с кэшированием, чтобы переиндексация оставалась дешёвой.
Проанализировать запрос
Входящие вопросы переписываются и на более глубоких тарифах разбиваются на подзапросы, чтобы составные вопросы извлекали нужные данные для каждой части.
Гибридный поиск и переранжирование
Векторные и ключевые результаты объединяются, затем переранжируются кросс-энкодером относительно вопроса, чтобы выдвинуть самые сильные фрагменты.
Собрать и ответить
К лучшим фрагментам присоединяется их родительский контекст, и они передаются модели, которая отвечает строго на основе извлечённых данных — с кэшированием результатов для повторяющихся вопросов.
Где обоснованные ответы окупаются
Создано для команд, чьи ответы должны быть точными
Снятие нагрузки с центра поддержки
Направьте агента на ваш центр поддержки и документацию по продукту, чтобы он сам решал типовые вопросы — точно и на основе ваших опубликованных ответов, ещё до того как понадобится человек.
Вопросы по внутренним политикам и регламентам
Загрузите ваши справочники, политики и стандартные процедуры, чтобы сотрудники получали чёткий ответ из утверждённого источника, а не искали по общему диску.
Ответы по документации продукта
Добавьте спецификации, руководства и примечания к выпускам, чтобы агент отвечал на детальные вопросы о продукте по реальной документации, а не по расплывчатому приближению.
Знания для онбординга и обучения
Превратите материалы для адаптации в базу знаний, которую новые сотрудники могут спрашивать простым языком — с опорой на то, что ваша команда действительно записала.