Recuperação / RAG
Respostas fundamentadas no seu próprio conhecimento
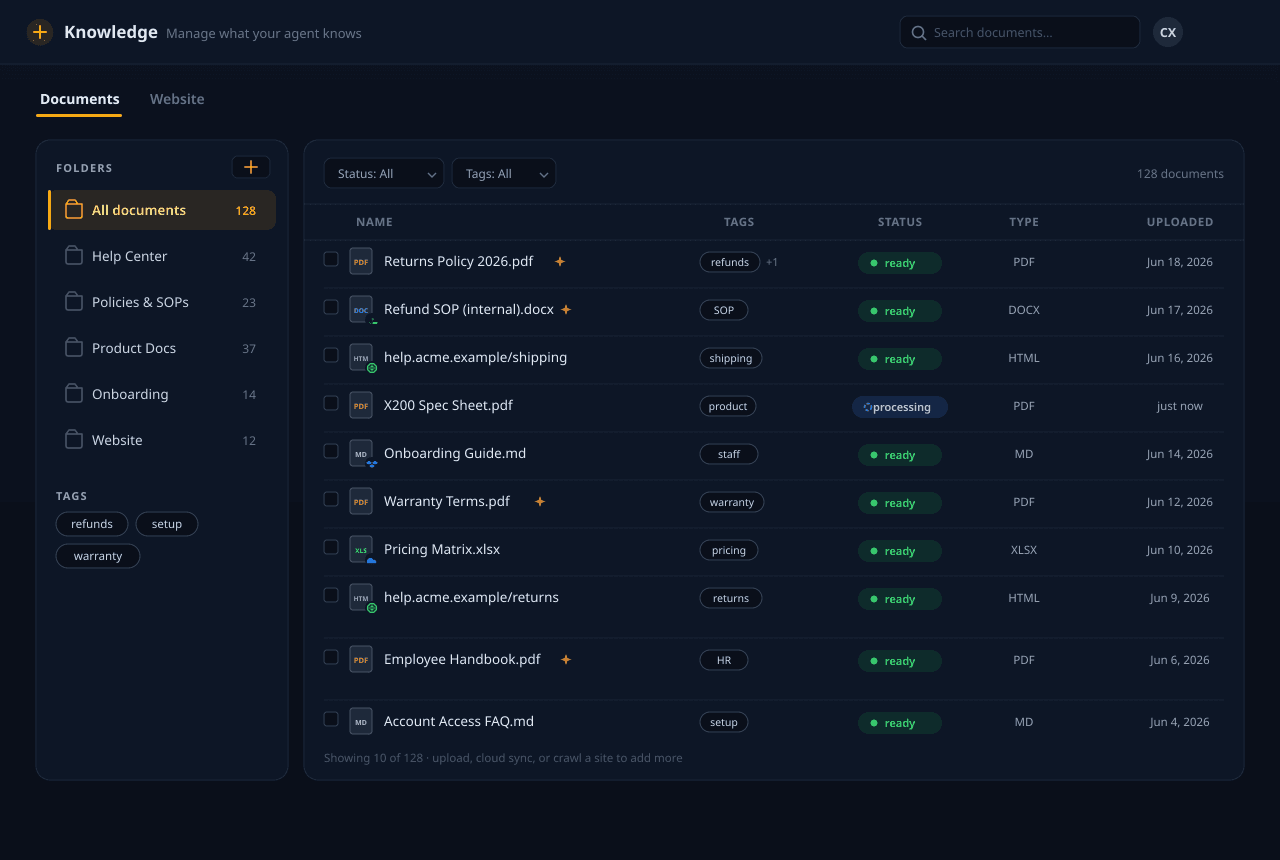
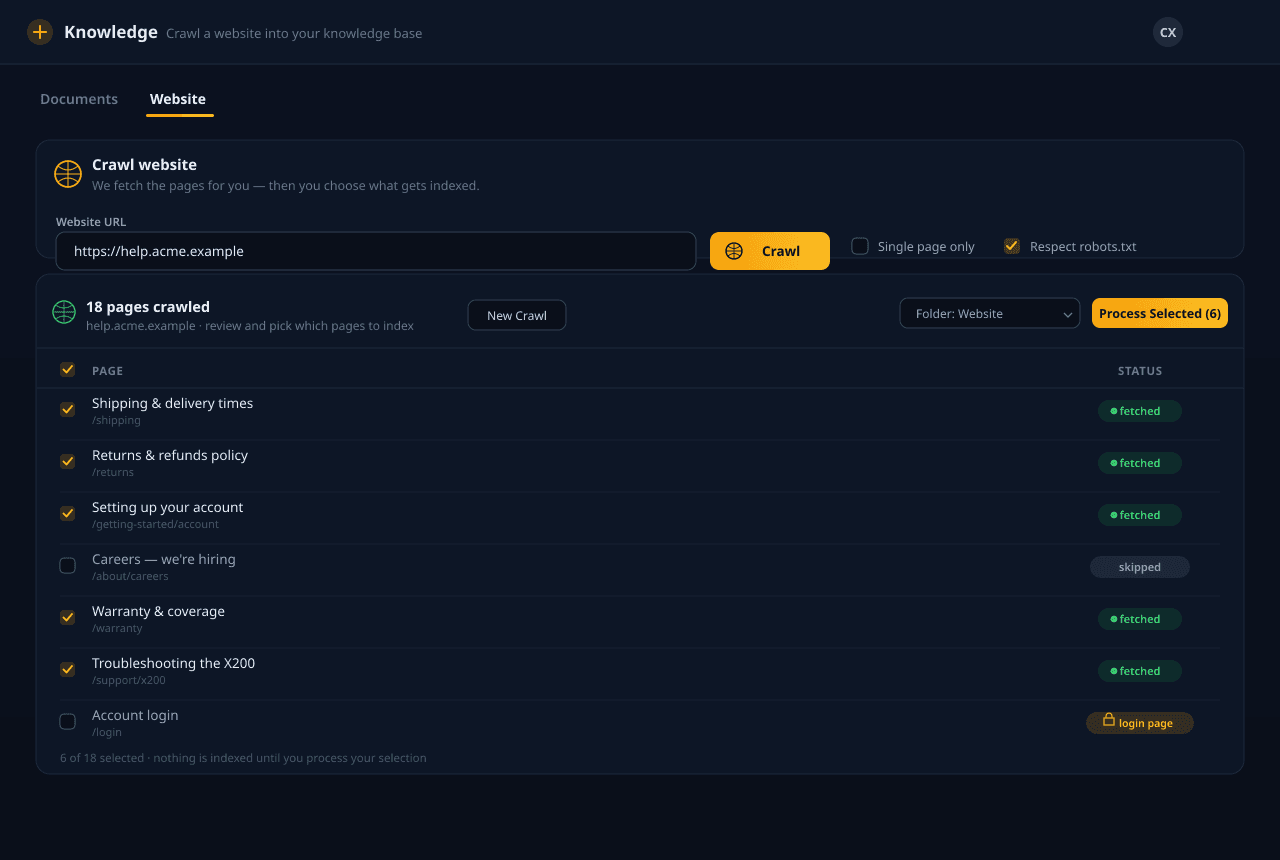
Envie seus documentos, aponte-nos para um site ou sincronize do armazenamento em nuvem. Analisamos, fragmentamos, enriquecemos e incorporamos tudo — e então recuperamos as passagens certas no momento da consulta para que seu agente responda com o que você realmente escreveu, não com suposições.
Veja o embasamento em ação
Respostas a partir das suas fontes, não suposições
Faça uma pergunta ao agente e veja de onde vem a resposta: dos seus próprios documentos, sites e arquivos enviados, nunca de uma resposta inventada.
Seu agente de conhecimento
Embase seu agente no seu próprio conhecimento
Embase seu agente no seu próprio conhecimento
O que o stack de recuperação faz
Ingira qualquer coisa
PDFs, documentos do Office, Markdown, HTML e sites inteiros — além de sincronização com Google Drive, Dropbox, OneDrive e Box. Nos planos pagos, lemos até PDFs digitalizados e baseados em imagem, tabelas complexas e manuscritos que os analisadores comuns deixam passar. Roteamos cada arquivo para o analisador certo e mantemos tudo em sincronia com a fonte.
Fragmentação contextual
Os documentos são divididos em fragmentos sobrepostos que respeitam a hierarquia, e cada fragmento é enriquecido com um breve resumo de contexto antes de ser incorporado — para que um fragmento ainda faça sentido por si só quando recuperado fora de ordem.
Busca híbrida
Cada consulta executa em paralelo a busca vetorial densa e a busca por palavras-chave (BM25), e então funde os resultados — capturando tanto correspondências semânticas quanto termos exatos como códigos de produto ou mensagens de erro que as incorporações puras não encontram.
Reranking
Um cross-encoder reordena os candidatos fundidos com base na pergunta real, levando as passagens genuinamente relevantes para o topo antes que cheguem ao modelo — menos quase-acertos, respostas mais precisas.
Contexto pai
Quando um fragmento pequeno corresponde, trazemos a seção pai ao seu redor para que o modelo veja a ideia completa, não uma frase recortada — um embasamento que parece ter entendido a página inteira.
Recuperação isolada por organização
Cada busca é limitada à sua organização. Sua base de conhecimento nunca é misturada com a de outra organização, nunca é usada para treinar modelos e é apagada quando você solicitar.
Do envio à resposta fundamentada
A indexação acontece uma vez no envio; a recuperação acontece a cada pergunta. Planos superiores liberam modos de consulta mais profundos que adicionam etapas como decomposição e reranking mais amplo — trocando um pouco de velocidade por respostas mais completas.
Analisar e fragmentar
Cada fonte é analisada por formato e dividida em fragmentos que respeitam a hierarquia, com sobreposição, preservando títulos e estrutura.
Enriquecer e incorporar
Cada fragmento recebe um breve resumo de contexto, depois é incorporado e enviado ao banco vetorial — em cache, para que a reindexação continue barata.
Analisar a consulta
As perguntas recebidas são reescritas e, nos planos mais profundos, decompostas em subconsultas para que perguntas de várias partes recuperem a evidência certa para cada parte.
Busca híbrida e reranking
Os resultados vetoriais e por palavras-chave são fundidos, depois reordenados por um cross-encoder com base na pergunta para destacar as passagens mais fortes.
Montar e responder
As melhores passagens recebem seu contexto pai anexado e são entregues ao modelo, que responde estritamente a partir da evidência recuperada — com resultados em cache para perguntas repetidas.
Onde respostas embasadas valem a pena
Feito para equipes cujas respostas precisam estar certas
Desvio de chamados na central de ajuda
Aponte o agente para a sua central de ajuda e a documentação de produto para que ele resolva as perguntas comuns sozinho, com precisão e a partir das suas respostas publicadas, antes de uma pessoa ser necessária.
Dúvidas sobre políticas e procedimentos internos
Carregue seus manuais, políticas e procedimentos padrão para que a equipe obtenha uma resposta clara da fonte aprovada em vez de vasculhar um drive compartilhado.
Respostas sobre documentação de produto
Adicione fichas técnicas, manuais e notas de versão para que o agente responda a perguntas detalhadas de produto a partir da documentação real, não de uma aproximação vaga.
Conhecimento de integração e treinamento
Transforme o seu material de integração em uma base de conhecimento que novos colaboradores podem consultar em linguagem natural, embasada no que a sua equipe de fato deixou registrado.