रिट्रीवल / RAG
जवाब जो आधारित हैं आपके अपने ज्ञान पर
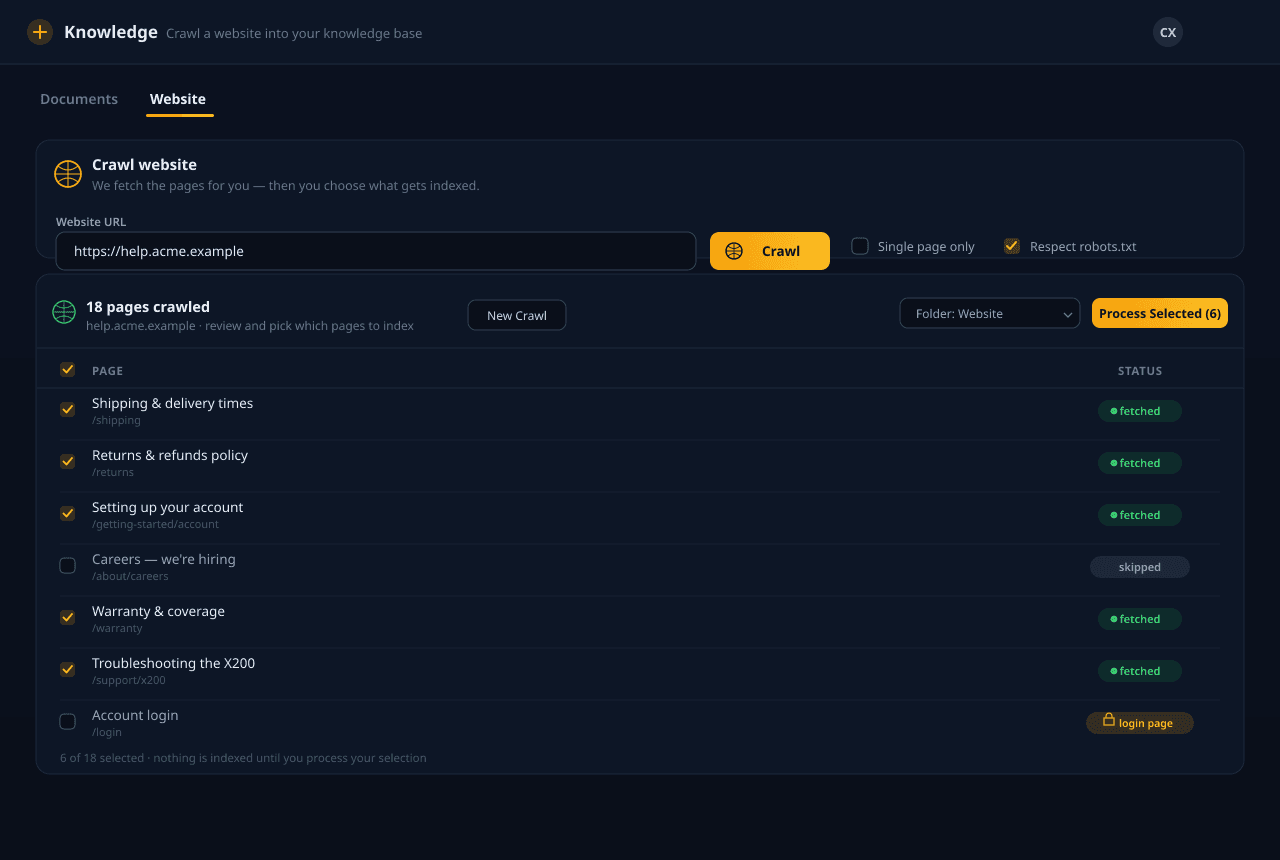
अपने दस्तावेज़ अपलोड करें, हमें किसी वेबसाइट की ओर इंगित करें, या क्लाउड स्टोरेज से सिंक करें। हम सब कुछ पार्स, चंक, समृद्ध और एम्बेड करते हैं — फिर क्वेरी समय पर सही अंश रिट्रीव करते हैं ताकि आपका एजेंट उसी से जवाब दे जो आपने वास्तव में लिखा, अनुमानों से नहीं।
स्रोत-आधारित जवाब क्रिया में देखें
आपके स्रोतों से जवाब, अनुमान नहीं
एजेंट से कोई सवाल पूछें और देखें कि जवाब कहाँ से आता है — आपके ही अपलोड किए दस्तावेज़ों, साइटों और फ़ाइलों से, कभी किसी गढ़े हुए जवाब से नहीं।
आपका नॉलेज एजेंट
अपने एजेंट को अपने ही ज्ञान पर आधारित करें
अपने एजेंट को अपने ही ज्ञान पर आधारित करें
रिट्रीवल स्टैक क्या करता है
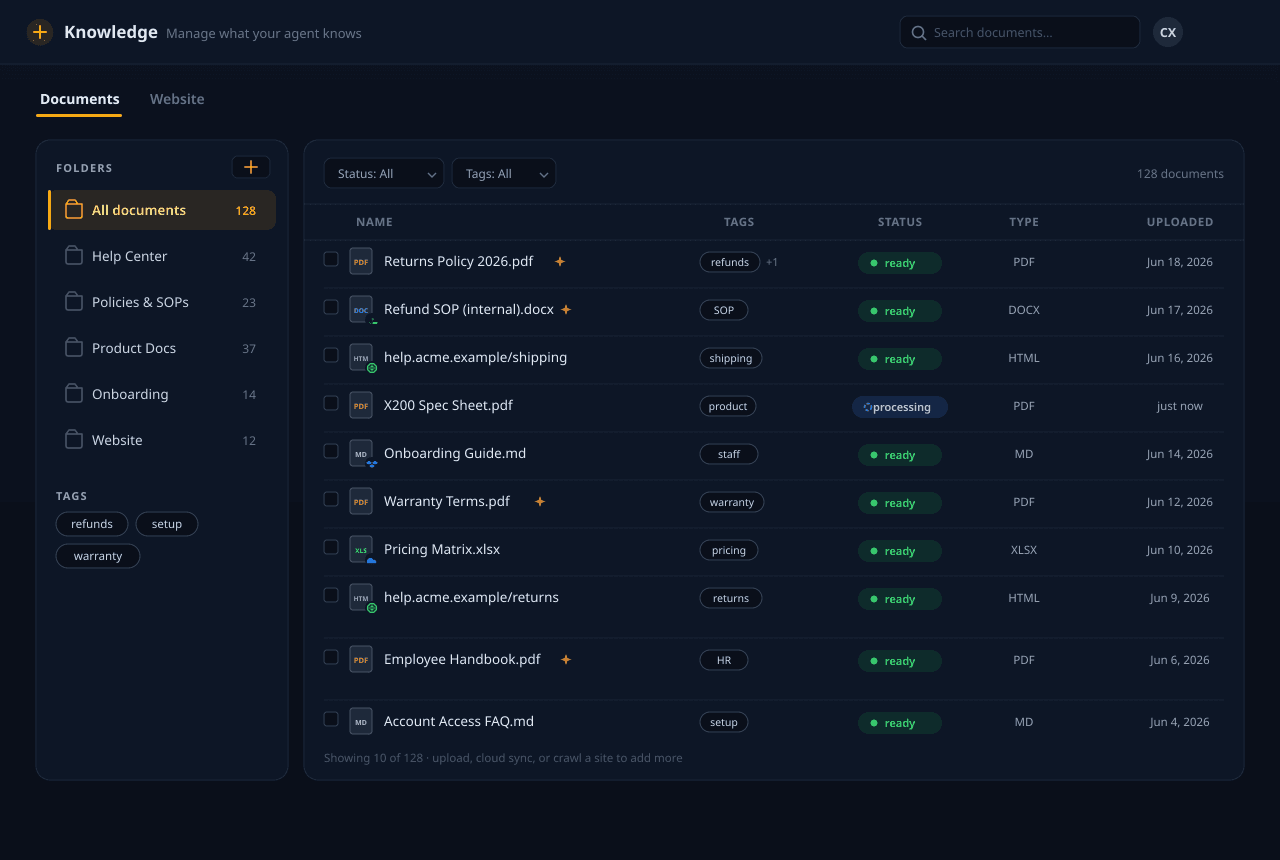
कुछ भी इन्जेस्ट करें
PDF, Office दस्तावेज़, Markdown, HTML और पूरी वेबसाइटें — साथ ही Google Drive, Dropbox, OneDrive और Box सिंक। सशुल्क प्लान पर हम स्कैन किए गए और छवि-आधारित PDF, जटिल तालिकाएँ और हस्तलेखन भी पढ़ते हैं, जिन्हें सामान्य पार्सर छोड़ देते हैं। हम हर फ़ाइल को सही पार्सर पर रूट करते हैं और सब कुछ स्रोत के साथ तालमेल में रखते हैं।
कंटेक्स्चुअल चंकिंग
दस्तावेज़ ओवरलैपिंग, पदानुक्रम-जागरूक चंक में बँटते हैं, और एम्बेडिंग से पहले हर चंक को एक छोटे संदर्भ सारांश से समृद्ध किया जाता है — ताकि कोई अंश क्रम से बाहर रिट्रीव होने पर भी अपने आप में समझ में आए।
हाइब्रिड खोज
हर क्वेरी समानांतर में डेंस वेक्टर खोज और कीवर्ड (BM25) खोज दोनों चलाती है, फिर परिणामों को मिलाती है — सिमैंटिक मैच और प्रोडक्ट कोड या एरर स्ट्रिंग जैसे सटीक शब्द, दोनों पकड़ती है जिन्हें शुद्ध एम्बेडिंग छोड़ देती है।
रीरैंकिंग
एक क्रॉस-एनकोडर मिले हुए उम्मीदवारों को वास्तविक सवाल के विरुद्ध फिर से रैंक करता है, और मॉडल तक पहुँचने से पहले ही वाकई-प्रासंगिक अंशों को ऊपर धकेलता है — कम चूक, तीक्ष्ण जवाब।
पैरेंट कंटेक्स्ट
जब कोई छोटा चंक मेल खाता है, हम उसका आसपास का पैरेंट सेक्शन खींच लाते हैं ताकि मॉडल पूरी सोच देखे, कटा हुआ वाक्य नहीं — ऐसी ग्राउंडिंग जो लगती है जैसे उसने पूरा पेज समझा हो।
टेनेंट-आइसोलेटेड रिट्रीवल
हर खोज आपके संगठन तक सीमित होती है। आपका नॉलेज बेस कभी किसी अन्य टेनेंट के साथ मिश्रित नहीं होता, कभी मॉडल प्रशिक्षण के लिए उपयोग नहीं होता, और अनुरोध पर मिटा दिया जाता है।
अपलोड से आधारित जवाब तक
इंडेक्सिंग आपके अपलोड करते समय एक बार होती है; रिट्रीवल हर सवाल पर होता है। ऊँची योजनाएँ गहरे क्वेरी मोड अनलॉक करती हैं जो डीकंपोज़िशन और व्यापक रीरैंकिंग जैसे चरण जोड़ते हैं — थोड़ी गति के बदले अधिक संपूर्ण जवाब।
पार्स और चंक
हर स्रोत प्रारूप के अनुसार पार्स होता है और ओवरलैप के साथ पदानुक्रम-जागरूक चंक में बँटता है, हेडिंग और संरचना को संरक्षित रखते हुए।
समृद्ध और एम्बेड
हर चंक को एक छोटा संदर्भ सारांश मिलता है, फिर एम्बेड होकर वेक्टर स्टोर में अपसर्ट होता है — कैश किया गया ताकि री-इंडेक्सिंग सस्ती रहे।
क्वेरी का विश्लेषण करें
आने वाले सवाल फिर से लिखे जाते हैं और, गहरे टियर पर, उप-क्वेरी में डीकंपोज़ किए जाते हैं ताकि बहु-भाग सवाल हर भाग के लिए सही साक्ष्य रिट्रीव करें।
हाइब्रिड खोज और रीरैंक
वेक्टर और कीवर्ड परिणाम मिलाए जाते हैं, फिर सबसे मज़बूत अंशों को सामने लाने के लिए एक क्रॉस-एनकोडर द्वारा सवाल के विरुद्ध फिर से रैंक किए जाते हैं।
असेंबल और जवाब
शीर्ष अंशों को उनका पैरेंट कंटेक्स्ट जोड़कर मॉडल को सौंपा जाता है, जो केवल रिट्रीव किए गए साक्ष्य से जवाब देता है — दोहराए गए सवालों के लिए कैश किए गए परिणामों के साथ।
जहाँ स्रोत-आधारित जवाब अपनी कीमत वसूल करते हैं
उन टीमों के लिए जिनके जवाब सही होने ही चाहिए
हेल्प सेंटर का बोझ घटाना
एजेंट को अपने हेल्प सेंटर और उत्पाद दस्तावेज़ों की ओर इंगित करें, ताकि किसी व्यक्ति की ज़रूरत पड़ने से पहले ही वह आम सवाल खुद हल कर दे — सटीकता से, आपके प्रकाशित जवाबों से।
आंतरिक नीतियों और प्रक्रियाओं पर प्रश्नोत्तर
अपनी हैंडबुक, नीतियाँ और मानक प्रक्रियाएँ लोड करें, ताकि कर्मचारी किसी साझा ड्राइव में खोजने के बजाय अनुमोदित स्रोत से सीधा जवाब पाएँ।
उत्पाद दस्तावेज़ों से जवाब
स्पेक शीट, मैनुअल और रिलीज़ नोट जोड़ें, ताकि एजेंट किसी अस्पष्ट अनुमान से नहीं, बल्कि असली दस्तावेज़ों से उत्पाद के विस्तृत सवालों के जवाब दे।
ऑनबोर्डिंग और प्रशिक्षण का ज्ञान
अपनी ऑनबोर्डिंग सामग्री को ऐसे नॉलेज बेस में बदलें जिसे नए कर्मचारी सहज भाषा में पूछ सकें — इस पर आधारित कि आपकी टीम ने वास्तव में क्या लिखकर रखा है।