Récupération / RAG
Des réponses ancrées dans votre propre savoir
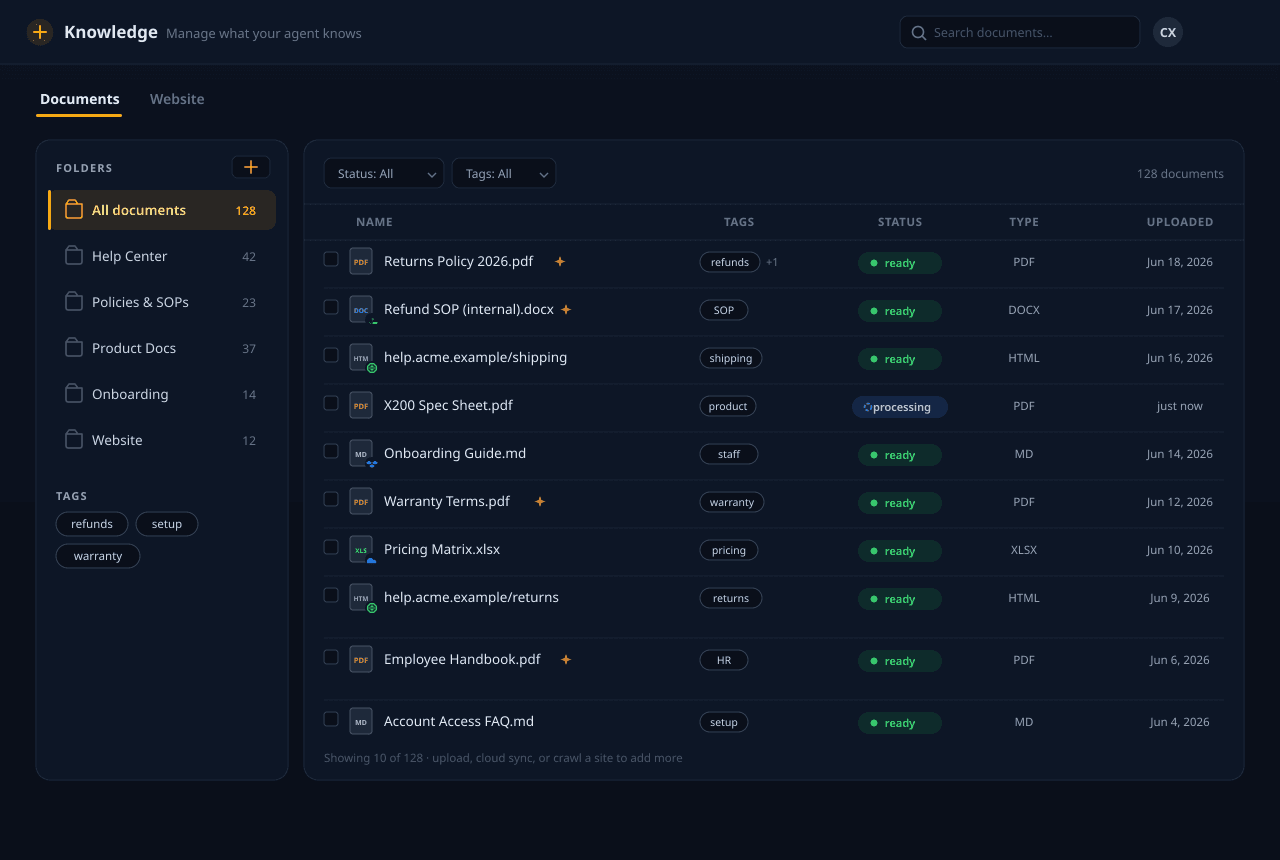
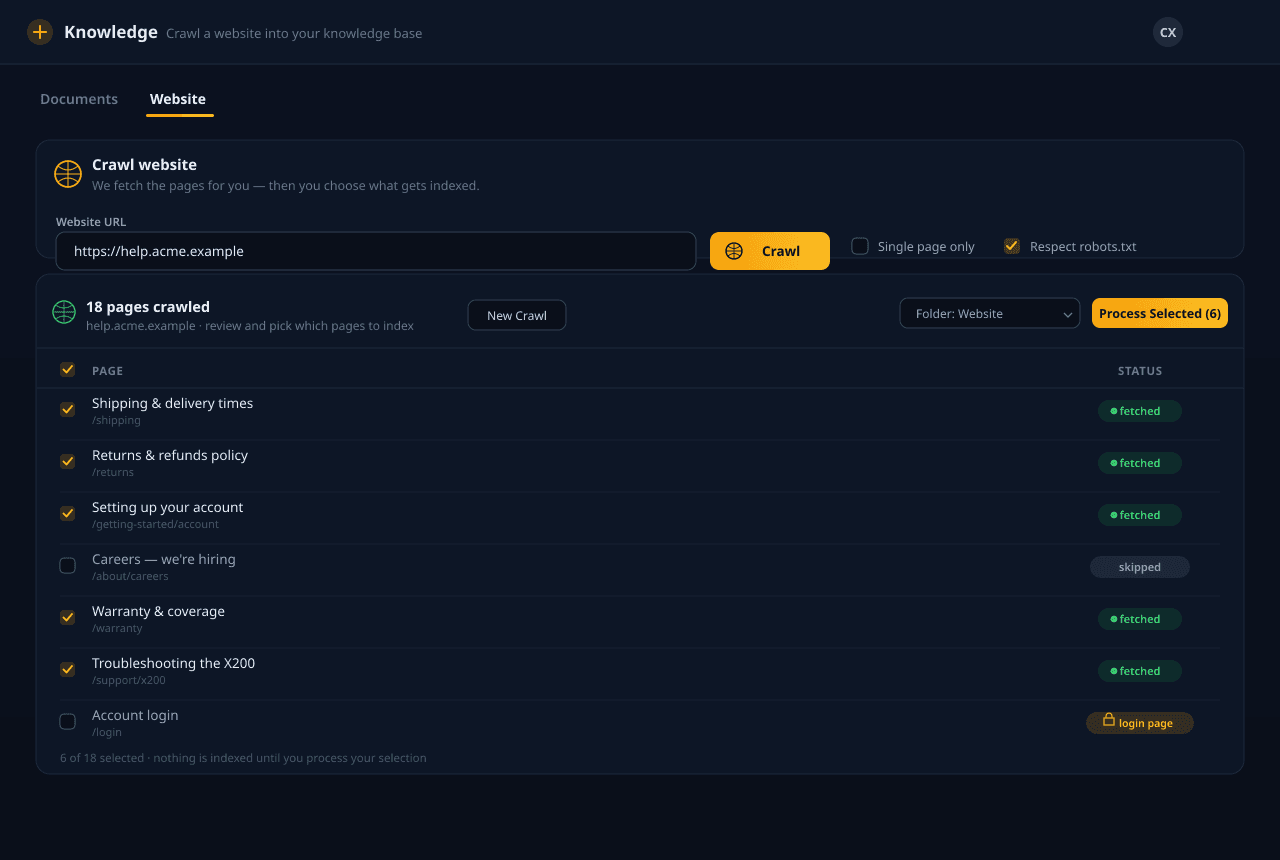
Importez vos documents, indiquez-nous un site web ou synchronisez depuis le stockage cloud. Nous analysons, segmentons, enrichissons et vectorisons tout — puis nous récupérons les bons passages au moment de la requête pour que votre agent réponde à partir de ce que vous avez réellement écrit, et non de suppositions.
Voyez l'ancrage en action
Des réponses tirées de vos sources, pas des suppositions
Posez une question à l'agent et voyez d'où vient la réponse : de vos propres documents, sites et fichiers importés, jamais d'une réponse inventée.
Votre agent de connaissances
Ancrez votre agent dans vos propres connaissances
Ancrez votre agent dans vos propres connaissances
Ce que fait la pile de récupération
Ingérer tout type de contenu
PDF, documents Office, Markdown, HTML et sites web entiers — ainsi que la synchronisation avec Google Drive, Dropbox, OneDrive et Box. Avec les forfaits payants, nous lisons même les PDF numérisés et basés sur des images, les tableaux complexes et l'écriture manuscrite que les analyseurs ordinaires laissent passer. Nous orientons chaque fichier vers le bon analyseur et gardons tout en phase avec la source.
Segmentation contextuelle
Les documents sont découpés en segments chevauchants respectant la hiérarchie, et chaque segment est enrichi d'un court résumé de contexte avant la vectorisation — pour qu'un fragment garde tout son sens lorsqu'il est récupéré hors séquence.
Recherche hybride
Chaque requête lance en parallèle une recherche vectorielle dense et une recherche par mots-clés (BM25), puis fusionne les résultats — captant à la fois les correspondances sémantiques et les termes exacts comme les codes produit ou les messages d'erreur que les vecteurs seuls manquent.
Reranking
Un cross-encoder reclasse les candidats fusionnés par rapport à la question réelle, faisant remonter les passages véritablement pertinents avant qu'ils n'atteignent le modèle — moins d'approximations, des réponses plus nettes.
Contexte parent
Quand un petit segment correspond, nous récupérons la section parente qui l'entoure pour que le modèle voie l'idée complète, et non une phrase tronquée — un ancrage qui donne l'impression d'avoir compris toute la page.
Récupération isolée par locataire
Chaque recherche est limitée à votre organisation. Votre base de connaissances n'est jamais mélangée à celle d'un autre locataire, jamais utilisée pour entraîner des modèles, et effacée sur demande.
De l'import à la réponse ancrée
L'indexation se fait une fois à l'import ; la récupération se fait à chaque question. Les forfaits supérieurs débloquent des modes de requête plus poussés qui ajoutent des étapes comme la décomposition et un reranking plus large — au prix d'un peu de rapidité pour des réponses plus complètes.
Analyser et segmenter
Chaque source est analysée selon son format et découpée en segments respectant la hiérarchie, avec chevauchement, en préservant les titres et la structure.
Enrichir et vectoriser
Chaque segment reçoit un court résumé de contexte, puis est vectorisé et inséré dans la base vectorielle — mis en cache pour que la réindexation reste peu coûteuse.
Analyser la requête
Les questions entrantes sont reformulées et, sur les forfaits plus poussés, décomposées en sous-requêtes pour que les questions à plusieurs volets récupèrent la bonne preuve pour chacun.
Recherche hybride et reranking
Les résultats vectoriels et par mots-clés sont fusionnés, puis reclassés par un cross-encoder selon la question pour faire ressortir les passages les plus solides.
Assembler et répondre
Les meilleurs passages reçoivent leur contexte parent et sont transmis au modèle, qui répond strictement à partir de la preuve récupérée — avec des résultats en cache pour les questions répétées.
Là où les réponses ancrées font la différence
Pensé pour les équipes dont les réponses doivent être justes
Déviation des demandes au centre d'aide
Orientez l'agent vers votre centre d'aide et votre documentation produit pour qu'il résolve seul les questions courantes, avec précision et à partir de vos réponses publiées, avant qu'une personne ne soit nécessaire.
Questions sur les politiques et procédures internes
Chargez vos manuels, politiques et procédures standard pour que vos équipes obtiennent une réponse claire issue de la source approuvée plutôt que de fouiller un disque partagé.
Réponses sur la documentation produit
Ajoutez fiches techniques, manuels et notes de version pour que l'agent réponde aux questions produit détaillées à partir de la vraie documentation, et non d'une approximation vague.
Connaissances d'intégration et de formation
Transformez votre matériel d'intégration en une base de connaissances que les nouveaux arrivants interrogent en langage naturel, ancrée dans ce que votre équipe a réellement consigné.