Recuperación / RAG
Respuestas basadas en tu propio conocimiento
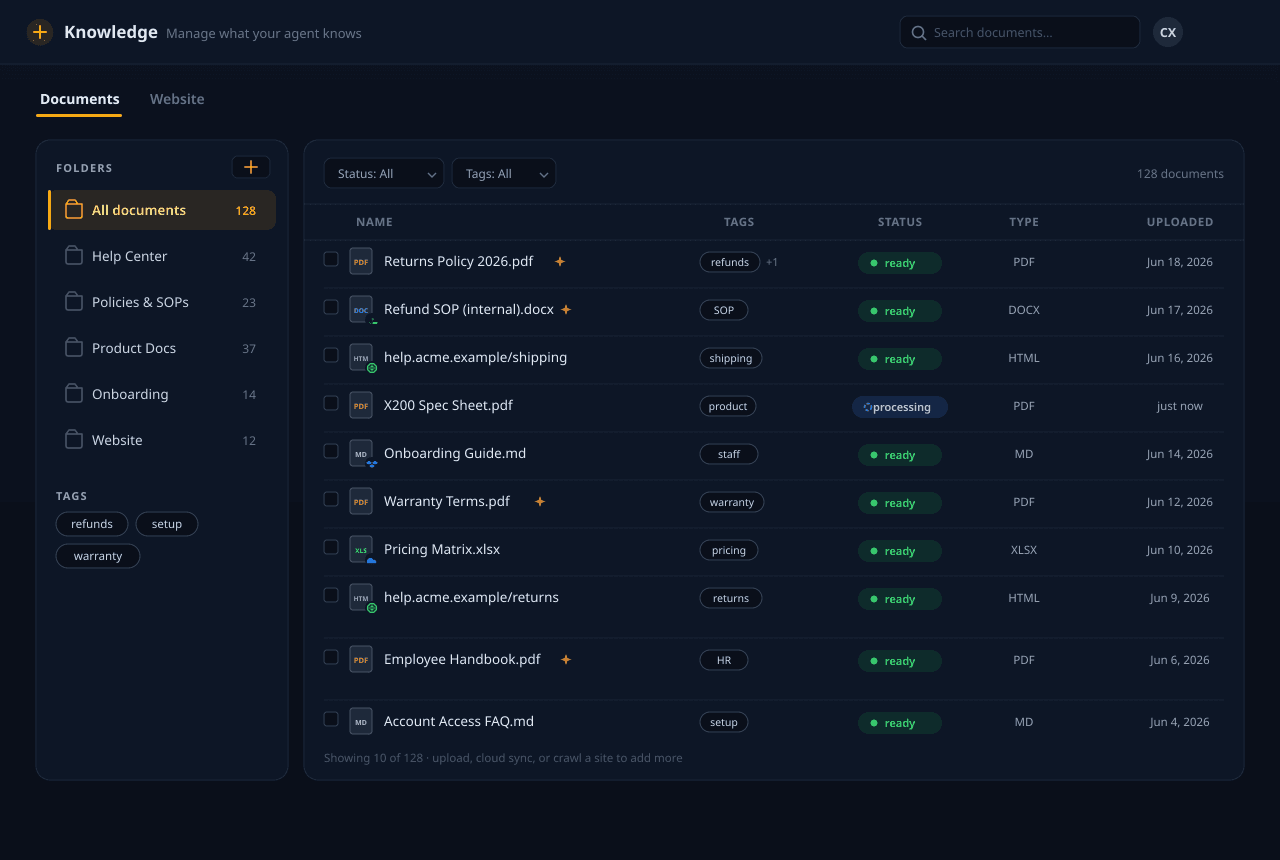
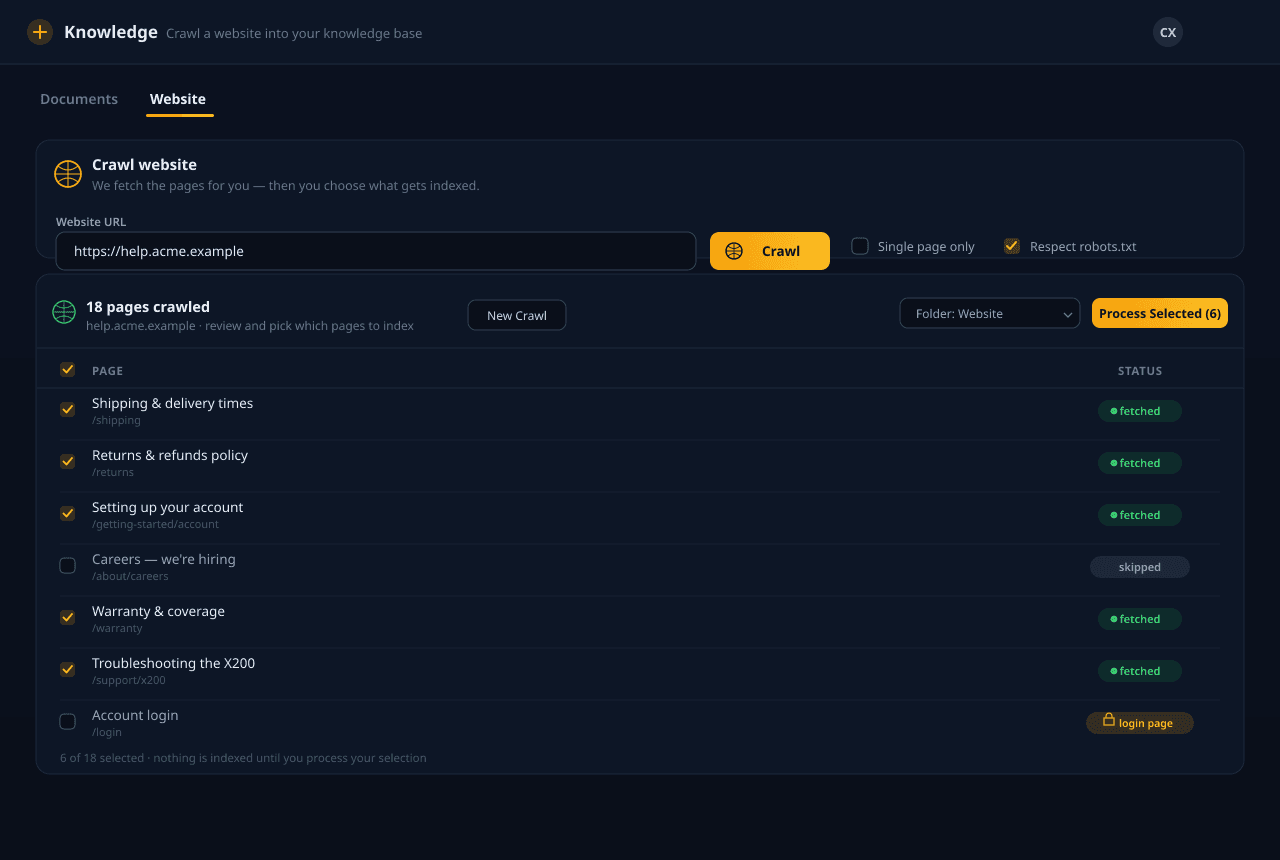
Sube tus documentos, apúntanos a un sitio web o sincroniza desde el almacenamiento en la nube. Analizamos, fragmentamos, enriquecemos e incrustamos todo — y luego recuperamos los pasajes correctos al momento de la consulta para que tu agente responda con lo que realmente escribiste, no con suposiciones.
Mira el fundamento en acción
Respuestas desde tus fuentes, no suposiciones
Hazle una pregunta al agente y observa de dónde sale la respuesta: de tus propios documentos, sitios y archivos subidos, nunca de una respuesta inventada.
Tu agente de conocimiento
Fundamenta tu agente en tu propio conocimiento
Fundamenta tu agente en tu propio conocimiento
Qué hace el stack de recuperación
Ingiere lo que sea
PDFs, documentos de Office, Markdown, HTML y sitios web completos — además de sincronización con Google Drive, Dropbox, OneDrive y Box. En los planes de pago incluso leemos PDF escaneados y basados en imágenes, tablas complejas y escritura a mano que los analizadores básicos pasan por alto. Enrutamos cada archivo al analizador correcto y mantenemos todo en sincronía con la fuente.
Fragmentación contextual
Los documentos se dividen en fragmentos superpuestos que respetan la jerarquía, y cada fragmento se enriquece con un breve resumen de contexto antes de incrustarse — para que un fragmento siga teniendo sentido por sí solo cuando se recupera fuera de orden.
Búsqueda híbrida
Cada consulta ejecuta en paralelo búsqueda vectorial densa y búsqueda por palabras clave (BM25), y luego fusiona los resultados — capturando tanto coincidencias semánticas como términos exactos como códigos de producto o cadenas de error que las incrustaciones puras se pierden.
Reranking
Un cross-encoder reordena los candidatos fusionados según la pregunta real, llevando los pasajes genuinamente relevantes a la cima antes de que lleguen al modelo — menos errores por aproximación, respuestas más precisas.
Contexto padre
Cuando un fragmento pequeño coincide, traemos la sección padre que lo rodea para que el modelo vea la idea completa, no una frase recortada — un fundamento que se lee como si hubiera entendido la página entera.
Recuperación aislada por inquilino
Cada búsqueda está limitada a tu organización. Tu base de conocimiento nunca se mezcla con la de otro inquilino, nunca se usa para entrenar modelos y se elimina cuando lo solicites.
De la carga a la respuesta fundamentada
La indexación ocurre una vez al subir; la recuperación ocurre en cada pregunta. Los planes superiores desbloquean modos de consulta más profundos que añaden pasos como la descomposición y un reranking más amplio — sacrificando un poco de velocidad por respuestas más completas.
Analizar y fragmentar
Cada fuente se analiza por formato y se divide en fragmentos que respetan la jerarquía, con superposición, preservando encabezados y estructura.
Enriquecer e incrustar
Cada fragmento recibe un breve resumen de contexto, luego se incrusta y se guarda en el almacén vectorial — en caché, para que reindexar siga siendo barato.
Analizar la consulta
Las preguntas entrantes se reescriben y, en los planes más profundos, se descomponen en subconsultas para que las preguntas de varias partes recuperen la evidencia correcta para cada parte.
Búsqueda híbrida y reranking
Los resultados vectoriales y por palabras clave se fusionan, luego se reordenan con un cross-encoder según la pregunta para destacar los pasajes más sólidos.
Ensamblar y responder
Los mejores pasajes reciben su contexto padre adjunto y se entregan al modelo, que responde estrictamente a partir de la evidencia recuperada — con resultados en caché para preguntas repetidas.
Donde las respuestas fundamentadas valen la pena
Hecho para equipos cuyas respuestas tienen que ser correctas
Desvío de tickets del centro de ayuda
Apunta el agente a tu centro de ayuda y a tus documentos de producto para que resuelva las preguntas comunes por sí solo, con precisión y desde tus respuestas publicadas, antes de que se necesite a una persona.
Preguntas sobre políticas y procedimientos internos
Carga tus manuales, políticas y procedimientos estándar para que el personal obtenga una respuesta clara de la fuente aprobada en lugar de buscar en una unidad compartida.
Respuestas sobre documentación de producto
Añade fichas técnicas, manuales y notas de versión para que el agente responda preguntas detalladas de producto desde la documentación real, no desde una aproximación vaga.
Conocimiento de incorporación y formación
Convierte tu material de incorporación en una base de conocimiento que las personas nuevas puedan consultar en lenguaje natural, fundamentada en lo que tu equipo realmente dejó por escrito.